Table.Schema()的唯一参数的数据类型为表格。该函数的结果为一表格,其第一列从上至下的文本值对应参数表从左到右的字段名称。从第二列开始,每一列中的值为同一行的第一列中的文本值对应于参数表中的字段的某一特征(比如:该字段的数据类型)。类似于Table.Profile(),Table.Schema()主要用于辅助完成以参数表的字段为对象的操作。
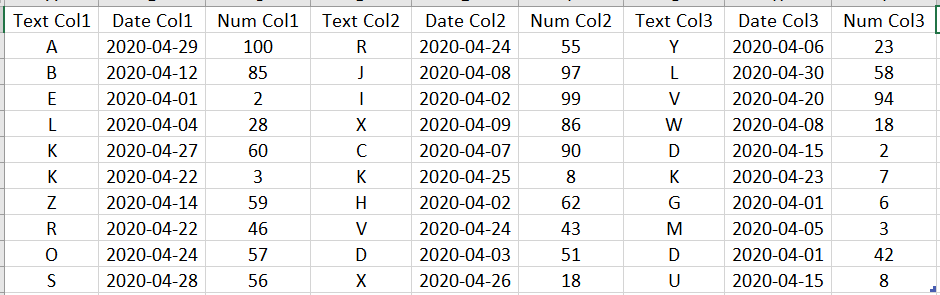
上图为共有9列的表格DB(其中三列的数据类型为文本,另外三列的为日期,剩下三列的为数字),该表格代入Table.Schema()后产生以下表格(DBSchema):
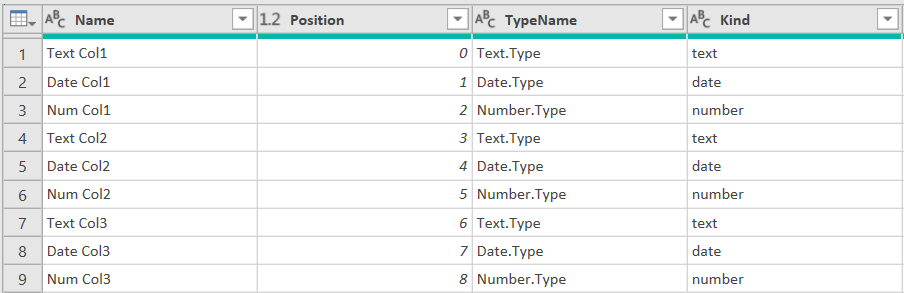
充分利用上表提供的信息,可以基于字段的数据类型对DB进行分割:
let
Source=
Table.Group(
DBSchema,
"TypeName",
{
"ByDataType",
each Table.SelectColumns( DB, [Name] )
}
)
in
Source
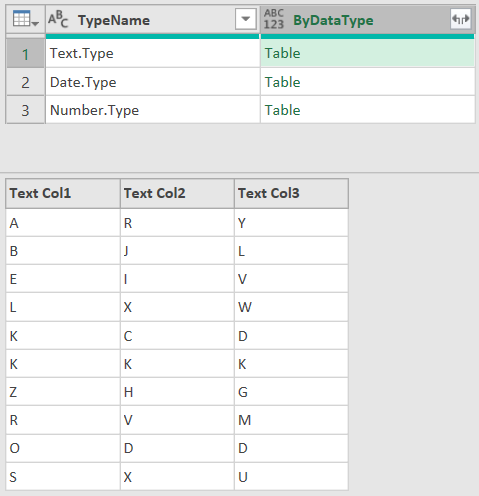
对DBSchema按TypeName进行分组后,分别把DB与分组结果的Name字段传入Table.SelectColumns()的第一和第二参数,就完成基于数据类型对DB表进行分割。如果需要颠倒DB表的字段次序,可以使用以下代码:
let
Source=
Table.ReorderColumns(
DB,
Table.Column(
Table.ReverseRows( DBSchema ),
"Name"
)
)
in
Source
因为DBSchema从上至下记录着DB从左到右的字段名称,所以只需要颠倒DBSchema的行顺序并把由Name字段转化而来的串列传入Table.ReorderColumns()就完成颠倒DB表的字段次序。如果想把DB表中字段的次序为偶数的分为一组而奇数的分为第二组,可以使用下代码:
let
Partition=
Table.Partition(
DBSchema,
"Position",
2,
each _
),
ToTable=
List.Transform(
Partition,
each
Table.SelectColumns(
DB,
Table.Column( _, "Name" )
)
)
in
ToTable
以上代码首先按Position的奇偶性把DBSchema分为两组,然后使用List.Transform()历遍分组所得的串列,最后使用Table.Column()提取每一组的Name字段并传入Table.SelectColumns()就完成按列次序的奇偶性对DB进行分割。使用Table.Schema()产生的信息,还可以构建type table []用来还原因为某些操作(在以下案例该操作为Table.TransformRows())而丢失的数据类型,首先需要在DBSchema中添加一计算列:
let
Source = Table.Schema( DB ),
AddCol=
Table.AddColumn(
Source,
"TypeCol",
each
Text.Combine(
{
Expression.Identifier( [Name] ),
[Kind]
},
" = "
),
type text
),
Buffering = Table.Buffer( AddCol )
in
Buffering
由于DB表的字段名称中间是含有空格的,所以需要使用Expression.Identifier()把"字段名称"转化为#"字段名称"。然后,需要使用Text.Combine()把转化后的字段名称与同一行的Kind值通过" = "连接起来。添加计算列之后,还需要以下的操作:
let
TableTypeInText=
Text.Combine(
{
"type table [ ",
Text.Combine(
Table.Column( DBSchema, "TypeCol" ),
", "
),
" ]"
}
),
Transformation=
Table.FromRecords(
Table.TransformRows(
DB,
(x) ⇒
Record.TransformFields(
x,
{
"Num Col1",
each _ + x[#"Num Col2"]
}
)
),
Expression.Evaluate( TableTypeInText )
)
in
Transformation
首先需要使用Table.Column()把计算列提取出来转化为串列,然后使用Text.Combine()通过", "把串列中的每一个元素连接起来,之后只要在连接好的文本头部添加"type table [ "以及尾部添加" ]"就构造好Expression.Evaluate()需要的文本。如果一开始没有在DBSchema中添加计算列,代码会变得比较长:
let
TableTypeInText=
Text.Combine(
{
"type table [ ",
Text.Combine(
Table.Column(
Table.CombineColumns(
Table.TransformColumns(
DBSchema,
{
"Name",
each Expression.Identifier( _ )
}
),
{ "Name", "Kind"},
Combiner.CombineTextByDelimiter(" = ", QuoteStyle.None ),
"MergedCol"
),
"MergedCol"
),
", "
),
" ]"
}
),
Transformation=
Table.FromRecords(
Table.TransformRows(
DB,
(x) ⇒
Record.TransformFields(
x,
{
"Num Col1",
each _ + x[#"Num Col2"]
}
)
),
Expression.Evaluate( TableTypeInText )
)
in
Transformation
首先,需要使用Table.TransformColumns()对DBSchema中的Name列进行转换,把"字段名称"转换为#"字段名称"。然后,使用Table.CombineColumns()合并转换后的Name列与Kind列,并限定这两列的每一行的两个值通过" = "连接起来。接着,使用Table.Column()把合并的列取出来化作串列,并使用Text.Combine()通过", "把每一个元素连接成一个新的文本值。在这个文本值的头部增添"type table [ "以及尾部增添" ]",就得到Expression.Evaluate()需要的文本。如果一开始没有在DBSchema添加计算列,也可以通过以下代码构建type table []的文本值:
let
TableTypeInText=
Text.Combine(
{
"type table [ ",
Text.Combine(
List.Transform(
Table.ToRows(
Table.SelectColumns(
Table.TransformColumns(
DBSchema,
{
"Name",
each Expression.Identifier( _ )
}
),
{ "Name", "Kind" }
)
),
each Text.Combine( _, " = ")
),
", "
),
"]"
}
),
Transformation=
Table.FromRecords(
Table.TransformRows(
DB,
(x) ⇒
Record.TransformFields(
x,
{
"Num Col1",
each _ + x[#"Num Col2"]
}
)
),
Expression.Evaluate( TableTypeInText )
)
in
Transformation
与上一种方法类似,一开始需要通过使用Table.TransformColumns()把"字段名称"转换为#"字段名称",然后使用Table.SelectColumns()移除除了Name与Kind之外的列。这时,DBSchema表格剩下两列,把它传入Table.ToRows()就可以以行为单位分解为{{}..{}}形式的复合串列,里面的每一个元素可以概括为{"Name", "Kind"}。在下一步中, 使用List.Transform()历遍这个复合串列,使其中的每一个元素从{"Name", "Kind"}转化为"Name = Kind"。接着,使用Text.Combine()把每一"Name = Kind"通过", "连接起来形成一个新的文本值。在这个文本值的头部添加"type table [ "以及在尾部添加" ]"就得到Expression.Evaluate()需要的文本值。其实,这个问题也十分适合使用Table.TransofrmRows()解决:
let
TableTypeInText=
Text.Combine(
{
"type table [",
Text.Combine(
Table.TransformRows(
DBSchema,
(x) ⇒
Record.Field(
Record.TransformFields(
x,
{
"Name",
each
Text.Combine(
{
Expression.Identifier( _ ),
x[Kind]
},
" = "
)
}
),
"Name"
)
),
", "
),
"]"
}
),
Transformation=
Table.FromRecords(
Table.TransformRows(
DB,
(x) ⇒
Record.TransformFields(
x,
{
"Num Col1",
each _ + x[#"Num Col2"]
}
)
),
Expression.Evaluate( TableTypeInText )
)
in
Transformation
首先,Table.TransformRows()把DBSchema以行为单位拆解为记录。然后,Record.TransformFields()对每一个记录的Name字段进行转换:(1)Expression.Identifier()把"字段名称"转换为#"字段名称"(2)#"字段名称"与同一记录中的Kind的值通过" = "连接起来。接着,使用Record.Field()把记录化为值,这样Table.TransformRows()的结果就变成{Value..Value},每一个Value可以概括为:#"字段名称" = Kind。接下来,使用Text.Combine()把Table.TransformRows()的结果通过", "连接起来成为新的文本值。最后在该文本值的头部添加"type table ["以及尾部添加" ]"就得到Expression.Evaluate()需要的文本值。
看这个文章对着excel文件看,效率会提高很多,不然有些地方单靠想还是有点晕的???