Splitter类函数即拆分器函数,为Table.SplitColumn的参数函数,共有如下9个。
| 函数名 | 解释 | 类型 |
|---|---|---|
| Splitter.SplitByNothing | 返回不拆分且将其自变量作为单元素列表返回的函数。 | |
| Splitter.SplitTextByAnyDelimiter | 返回一个函数,它在任意指定的分隔符处将文本拆分为文本列表。 | 按分隔符 |
| Splitter.SplitTextByDelimiter | 返回一个函数,它根据指定的分隔符将文本拆分为文本列表。 | 按分隔符 |
| Splitter.SplitTextByEachDelimiter | 返回一个函数,它依次在每个指定的分隔符处将文本拆分为文本列表。 | 按分隔符 |
| Splitter.SplitTextByLengths | 返回一个函数,它按每个指定的长度将文本拆分为文本列表。 | 按字符数 |
| Splitter.SplitTextByPositions | 返回一个函数,它在每个指定的位置将文本拆分为文本列表。 | 按字符数 |
| Splitter.SplitTextByRanges | 返回一个函数,它根据指定的偏移量和长度将文本拆分为文本列表。 | 按字符数 |
| Splitter.SplitTextByRepeatedLengths | 返回一个函数,它在指定的长度后反复将文本拆分为文本列表。 | 按字符数 |
| Splitter.SplitTextByWhitespace | 返回一个函数,它在空白处将文本拆分为文本列表。 |
通过观察以上的说明可以发现,返回的都是将文本拆成list的函数,其本质就是each {}的形式,只不过用了这些看起来更加专业的拆分器函数。
由于数量较多,还是结合界面操作来讲。可以分为3类,第一类是按分隔符,第二类是按字符数或者说叫按位置,第三类即
Splitter.SplitByNothing和Splitter.SplitTextByWhitespace,暂且就分为没什么卵用类吧。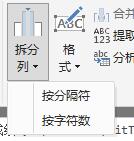
先看自动生成的公式,比如选按逗号分隔,拆分位置为"最左侧的分隔符",主要看splitter的部分:
Splitter.SplitTextByEachDelimiter({","}, QuoteStyle.Csv, false)
共三个参数,第一参数为指定的分割符,这个一会再讲;第二参数为
QuoteStyle.Type,有两个参数可选分别为QuoteStyle.None和QuoteStyle.Csv,可以分别用0和1代替。也就是下图界面中的"引号字符"选项,实际上并没有什么卵用,一般可以省略。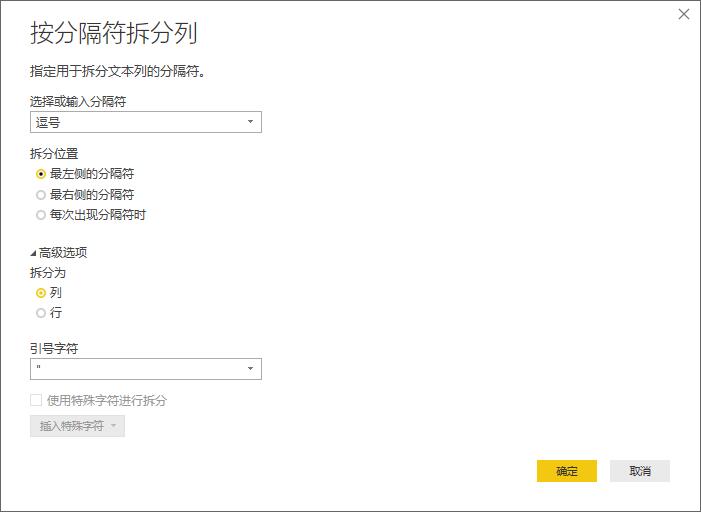
第三参数为靠左还是靠右,false为靠左,true为靠右,也就是上图中"最左侧的分隔符"和"最右侧的分隔符"的区别。
= Table.SplitColumn(源, "成绩",Splitter.SplitTextByEachDelimiter({","},null,true))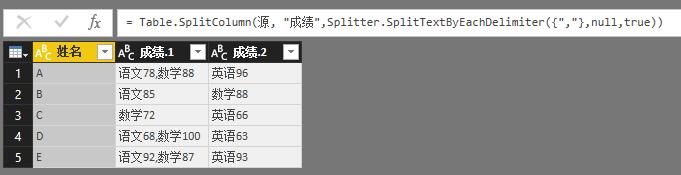
下面开始一个个过,先看第一类按分隔符。有三个函数,其中ByDelimiter只有两个参数,没有最后一个靠左靠右模式的参数,第一参数为text。ByAnyDelimiter和ByEachDelimiter都有三个参数,第一参数都为list。
ByDelimiter就是只指定一个分隔符,全部按这个分隔符拆,遇到就拆,这个不难理解。
ByAnyDelimiter则是上一个的加强版,也是见一次拆一次,但是它的第一参数可以以list的形式指定多个分隔符,比如{","," "}就是遇到逗号和空格都拆。但它竟然也有第三参数的靠左靠右模式,反正我是想不通有什么存在的意义,暂且省略不填吧。
ByEachDelimiter第一参数也是list,但不同的是列表中的每个分隔符都是指定位置的。你可以想象成在纸上把列表中的分隔符都写出来,比如{","," "},那么遇到第一个逗号进行一次拆分,然后把逗号划掉,后面再遇到就不拆了,再找下一个分隔符继续拆分。此时的第三参数就有意义了,填true和false决定了是按从左还是从右的顺序开始找分隔符。
再看第二类按字符数拆分,发现区别不大,拆分函数变了
Splitter.SplitTextByRepeatedLengths(3),又试一下靠左模式,Splitter.SplitTextByPositions({0,3},false)。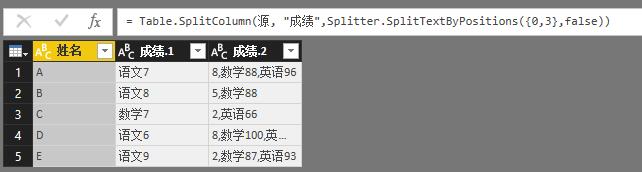
第一参数就是第一节拆分出来的字符串的位置边界,尝试改改这个边界:
Splitter.SplitTextByPositions({2,6},false)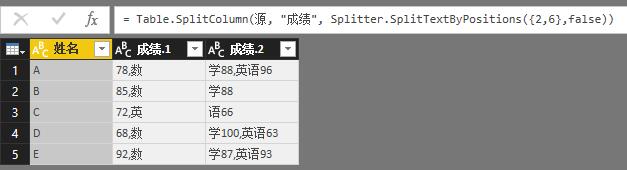
再试下
Splitter.SplitTextByPositions({0,3,6,9},false))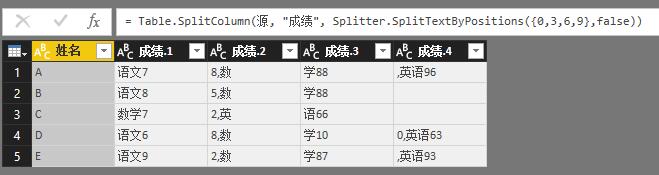
让我想到菜市场卖肉的师傅说:指哪儿切哪儿。。。
Splitter.SplitTextByLengths({3,3,3,99},false)表示不服!你有我够直接吗?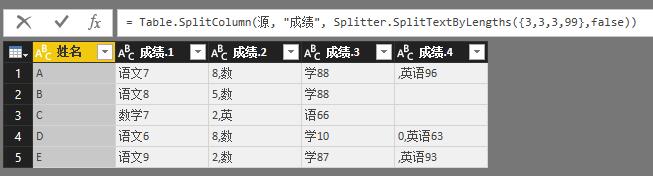
还有一个
Splitter.SplitTextByRanges没讲到,Splitter.SplitTextByRanges({{0,3},{3,6}},false)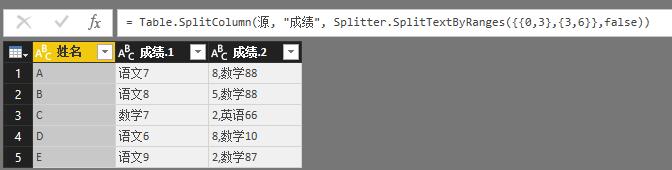
语法为{{初始点1,长度1},{初始点2,长度2},...}
至于第三类没什么卵用类的
Splitter.SplitTextByWhitespace,Splitter.SplitByNothing,我是真的暂时还没发现它们有什么卵用。。。当然,spiltter类函数不仅只能作为
Table.SplitColumn的参数,也可以拿出来单独使用,如果我们在编辑栏填上参数: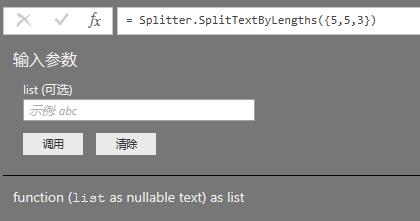
可以看到返回的还是一个函数,那我们在后面再次给一个list参数,就能够按照指定的规则将文本分割:
= Splitter.SplitTextByLengths({5,5,3})("powerquery爱好者")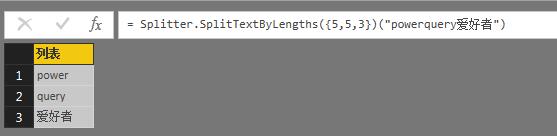
目前我碰到一個問題是:我由SAP系統下載一個報表檔案,在還沒切割成個欄位時,每筆資料長度均為165 bytes。但資料中有英文,也有中文字(2 bytes)。以長度切割時,Power Query視一個中文字及一個英文字母都是1,無法照我想要的方法Split。不知道你是否有更好的方法Split夾雜中英文的資料??
用Text.Remove/Text.Select
ByAnyDelimiter在下面的情況出來就有分別了, 可是沒搞懂為啥true的時候"E1,E2,E3"從右邊開始E3就不見了?
我試過獨立只用D的行是會出3列的,可是ABCD 4行做的話就只有2列了
let
Source = #table({"Name", "Score"},{{"A","C1,C2,""C3;3"";4"""}, {"B","C1,""C2,C3"""}, {"C","""D1,D2"",D3"}, {"D","E1,E2,E3"}}),
#"startatend is false" = Table.SplitColumn(Source, "Score", Splitter.SplitTextByAnyDelimiter({",", ";"}, QuoteStyle.Csv, false)),
#"startatend is true" = Table.SplitColumn(Source, "Score", Splitter.SplitTextByAnyDelimiter({",", ";"}, QuoteStyle.Csv, true))
in
#"startatend is true"
Source = #table({"Name", "Score"},{{"D","E1,E2,E3"},{"A","C1,C2,""C3;3"";4"""}, {"B","C1,""C2,C3"""}, {"C","""D1,D2"",D3"}})
把Source改成D先走的話就出來的, 看來是以第一行拆分出來的列數來判定的
不然就自己加參數
#"startatend is true" = Table.SplitColumn(Source, "Score", Splitter.SplitTextByAnyDelimiter({",", ";"}, QuoteStyle.Csv, true),3)
拆分函数主要用于有间隔符、长度、位置有规律的,如果是复杂的需要嵌套运算或者PowerQuery支持Js的正则表达式,专业拆分和提取