IT部门的同事不时会扭曲数据使用者的意图,设计出不合理的数据布局,其中比较常见的不合理布局为同一字段含有性质不同的值。假如数据使用者需要如下图的数据:

不幸的是,IT部门的同事提供的的数据为:
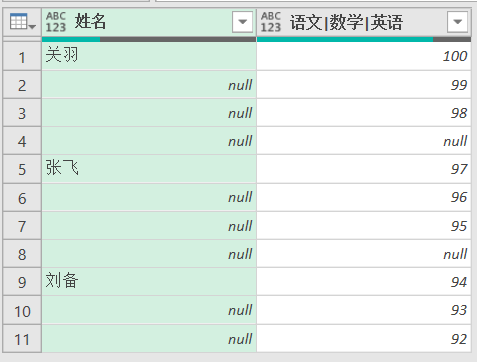
如果IT部门的同事拒绝修改以上数据的布局,请使用以下的代码:
let
Source = Excel.CurrentWorkbook(){[Name="Case1"]}[Content],
DataType=
Table.TransformColumnTypes(
Source,
{
{ "姓名", type text },
{ "语文|数学|英语", Int64.Type }
}
),
RemoveNullRows1 = Table.SelectRows( DataType, each ( #"语文|数学|英语"] ‹› null ) ),
Indexing = Table.AddIndexColumn( RemoveNullRows1, "Index", 0, 1),
Mod3=
Table.AddColumn(
Indexing,
"Modulo",
each Text.From( Number.Mod( [Index], 3 ) ),
type text
),
Pivoting = Table.Pivot( Mod3, { "0".."2" }, "Modulo", "语文|数学|英语" ),
Sorting = Table.Sort( Pivoting, { "Index", Order.Ascending } ),
FillUp = Table.FillUp( Sorting, { "1", "2" } ),
RemoveNullRows2 = Table.SelectRows( FillUp, each [姓名] ‹› null ),
RemoveCol = Table.RemoveColumns( RemoveNullRows2, { "Index" } ),
RenameCols = Table.RenameColumns(
RemoveCol,
{
{ "0", "语文" },
{ "1", "数学" },
{ "2", "英语" }
}
)
in
RenameCols
由于刘关张学习的科目总共有3科,所以你需要使用对行数指数求整数3的模数,达到分组的目的。之后再对模数进行枢纽化,令到语文成绩所在行在枢纽化后得到的三个列的值为某人的语文成绩紧接着两个空值,而数学成绩所在行在枢纽化后得到的三个列的值为两个空值夹着数学成绩,最后英语成绩所在行在枢纽化后得到的三个列的值为两个空值紧随着英语成绩。接着,对列“2”和"3"进行向上填充就基本实现化列为行的效果。这个方法最大的好处是所有的步骤基本能够通过使用者界面的按钮完成,但是最大的缺点为如果要处理的列不止一行,以上代码的动作就需要重复多次。
假如你需要的数据为:

IT部门的同事提供的却是如下图所示的结构,并且拒绝修改。
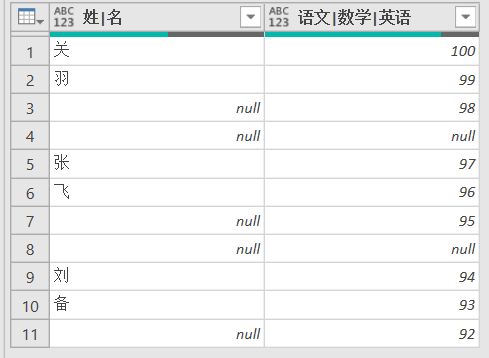
为了得到期望的数据布局,请使用以下代码:
let
Source = Excel.CurrentWorkbook(){ [Name="Case2"] }[Content],
DataType1=
Table.TransformColumnTypes(
Source,
{
{ "姓|名", type text },
{ "语文|数学|英语", Int64.Type }
}
),
Grouping=
Table.Group(
DataType1,
"语文|数学|英语",
{ "GTable", each _ },
GroupKind.Local,
(x,y) ⇒
Number.From( y = null )
),
Transform=
List.Transform(
Grouping[GTable],
each
List.RemoveNulls(
List.Combine(
Table.ToColumns( _ )
)
)
),
ToTable=
Table.FromRows(
Transform,
List.Combine(
List.Transform(
Table.ColumnNames( DataType1 ),
each
Text.Split( _,"|" )
)
)
),
DataType2=
Table.TransformColumnTypes(
ToTable,
{
{ "姓", type text },
{ "名", type text },
{ "语文", Int64.Type },
{ "数学", Int64.Type },
{ "英语", Int64.Type }
}
)
in
DataType2
首先需要使用Table.Group()的局部分组把数据分为3组,然后通过Table.ToColumns()把代表每一组的表格按列分解为串列组,之后通过List.Combine()完成收尾相连,最后使用List.RemoveNulls()移除空值。完成一系列转换后的复合串列通过Table.FromRows()就可以得到想要的结果。
如果担心List.RemoveNulls()在数据比较多的情况下回应时间比较长,可以考虑使用以下代码:
let
Source = Excel.CurrentWorkbook(){[Name="Case2"]}[Content],
DataType1=
Table.TransformColumnTypes(
Source,
{
{ "姓|名", type text },
{ "语文|数学|英语", type text }
}
),
Grouping=
Table.Group(
DataType1,
"语文|数学|英语",
{ "GTable", each _ },
GroupKind.Local,
(x,y) ⇒
Number.From( y = null )
),
Transform=
List.Transform(
Grouping[GTable],
each
Text.Combine(
List.Combine(
Table.ToColumns( _ )
),
"|"
)
),
ToTable=
Table.FromList(
Transform,
Splitter.SplitTextByDelimiter( "|" ),
List.Combine(
List.Transform(
Table.ColumnNames( DataType1 ),
each
Text.Split( _,"|" )
)
),
null,
ExtraValues.Error
),
DataType2=
Table.TransformColumnTypes(
ToTable,
{
{"语文", Int64.Type},
{"数学", Int64.Type},
{"英语", Int64.Type}
}
)
in
DataType2
基本思路没有发生变化,只不过List.RemoveNulls()被替换成Text.Combine()后产生的结果为简单的串列而不是复合型的串列,所以该结果需要使用Table.FromList()还原为表格。
从喜欢这个案例的爱好者的回复中发现以上代码仍存在提升的空间, 经过改良的案例2解法1为:
let
Source = Excel.CurrentWorkbook(){[Name="Case2"]}[Content],
Grouping=
Table.Group(
Source,
"语文|数学|英语",
{
"GRecord",
each
Record.FromList(
List.RemoveNulls(
List.Combine(
Table.ToColumns( _ )
)
),
Text.Split(
Text.Combine(
Table.ColumnNames( _ ),
"|"
),
"|"
)
),
type record
},
GroupKind.Local,
( x , y ) ⇒ Number.From( y = null )
),
ToTable=
Table.FromRecords(
Grouping[GRecord],
type table [姓=text, 名=text, 语文=Int64.Type, 数学=Int64.Type, 英语=Int64.Type ]
)
in
ToTable
以上解法主要利用了Table.Group()的aggregatedColumns参数的第二个元素为表格的特点,对该表格进行一系列的处理使之转化为记录。由于深化(Drill Through)Table.Group()的结果的第二列将会产生串列套记录({[]..[]})的数据结构,可以把深化的结果传入Table.FromRecords()使之转化为表格。
经过改良的案例2的解法2:
let
Source = Excel.CurrentWorkbook(){[Name="Case2"]}[Content],
DataType1=
Table.TransformColumnTypes(
Source,
{
{ "姓|名", type text },
{ "语文|数学|英语", type text }
}
),
GroupSplit=
Table.SplitColumn(
Table.Group(
DataType1,
"语文|数学|英语",
{
"GText",
each
Text.Combine(
List.Combine(
Table.ToColumns( _ )
),
"|"
)
},
GroupKind.Local,
(x,y) ⇒ Number.From( y = null )
),
"GText",
Splitter.SplitTextByDelimiter( "|" ),
Text.Split(
Text.Combine(
Table.ColumnNames( DataType1 ),
"|"
),
"|"
)
),
DataType2=
Table.TransformColumnTypes(
GroupSplit,
{
{"语文", Int64.Type},
{"数学", Int64.Type},
{"英语", Int64.Type}
}
),
RemoveCol = Table.RemoveColumns( DataType2, {"语文|数学|英语"} )
in
RemoveCol
以上解法主要利用了Table.Group()的aggregatedColumns参数的第二个元素为表格的特点,对该表格进行一系列的处理使之转化为文本值,然后使用Table.SplitColumn()完成展开列的过程。
局部分组+recordfromlist 不香么 /托腮
使用Record.FromList()会更好吗?请指教一下。
香,我试了一下,代码更加清爽
这个问题整得有些复杂,不过下面的几个思路都很好,我这里献丑了。
let
源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
筛选 = Table.SelectRows(源, each [#"语文|数学|英语"] null),
填充 = Table.FillDown(筛选,{"姓名"}),
分组 = Table.Group(填充,
"姓名",
{
"n",
each
Table.FromRows(
List.Zip(
{
{"语文","数学","英语"}
,_[#"语文|数学|英语"]
}
)
,{"科目","成绩"}
)
}
),
展开 = Table.ExpandTableColumn(分组, "n", {"科目", "成绩"}),
透视 = Table.Pivot(展开, List.Distinct(展开[科目]), "科目", "成绩")
in
透视
对于case1不知道是不是这个意思
let
Source = Excel.CurrentWorkbook(){[Name="Case1"]}[Content],
筛选 = Table.SelectRows(Source, each ([#"语文|数学|英语"] null)),
填充= Table.FillDown(筛选,{"姓名"}),
获取列名=Text.Split(List.Skip(Table.ColumnNames(填充)){0},"|"),
分组=Table.Group(填充,"姓名",{{"a",each Record.FromList(_[#"语文|数学|英语"],获取列名)}}),
展开 = Table.ExpandRecordColumn(分组, "a", 获取列名, 获取列名)
in
展开
你的代码能解决Case1,获取列名多了一个多余的步骤,详情看看Case1_Method3
感觉做的太复杂了,直接用Table.Range分割,然后,一个人对一个Record,然后Record拆分成列 成了