Table.Split()可以抽象地概括为function(table as table, pageSize as number) as list,大概的意思为这个函数的第一个参数为需要进行自上而下地分割的表格,而第二个参数则指明了被分出来的表格至少有多少行。以下将通过回顾Table.Combine()中的情形2,说明这个函数的基础用法。
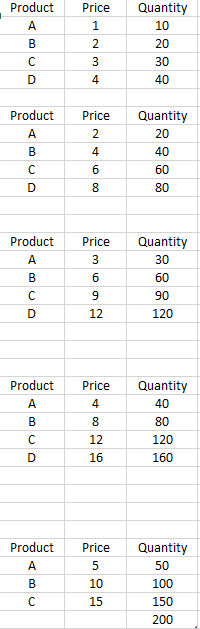
上图表格(Case2)记录了五间商铺的销售情况,每一间商铺销售的商品种类的数量相同,但是每一行的三列数据会随机缺失最多两列的数据,现在要求把上表转化为下表。
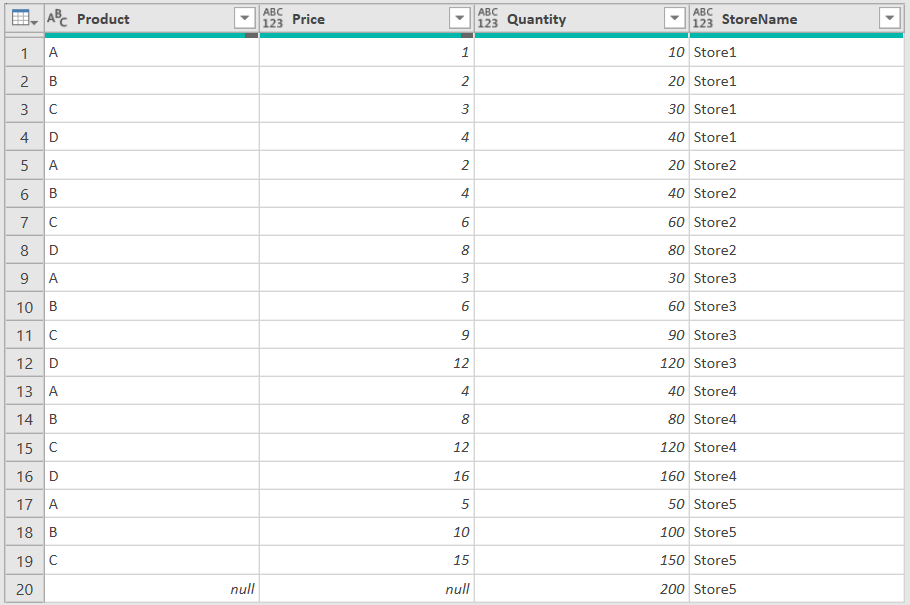
以下为使用了Table.Split()解决这个问题的代码:
let
ColNames= Table.ColumnNames( Case2 ),
Cleaning=
Table.RemoveMatchingRows(
Case2,
List.TransformMany(
{
List.Repeat(
{null},
Table.ColumnCount( Case2 )
),
ColNames
},
each { ColNames },
( x, y ) ⇒ Record.FromList( x, y )
)
),
Grouping=
Table.Split(
Cleaning,
Number.IntegerDivide(
Table.RowCount(Cleaning),
5
)
),
UnionAll=
Table.Combine(
List.Transform(
List.Numbers(
1,
List.Count(Grouping)
),
each
Table.AddColumn(
Grouping{ _- 1 },
"StoreName",
(x) ⇒
Text.Combine(
{
"Store",
Text.From( _ )
}
)
)
)
)
in
UnionAll
在Cleaning步骤中,首先通过List.TransformMany()构造出{[Product=null, Price=null, Quantity=null], [Product="Product", Price="Price", Quantity="Quantity"]}并传入Table.RemoveMatchingRows()的第二个参数,这样就把不需要的行移除了。因为假设了五家商铺出售的商品种类的数量相同,这种情形下只要算好每一家商铺出售的商品种类数量并传入Table.Split()就完成分组了。由于分组的结果为串列,之后需要通过List.Transform()历遍串列中的每一个元素并为每一个元素添加计算商铺名的列。最后,把添加了计算列的子表格通过使用Table.Combine()重新组合起来就完成了需要的转换。
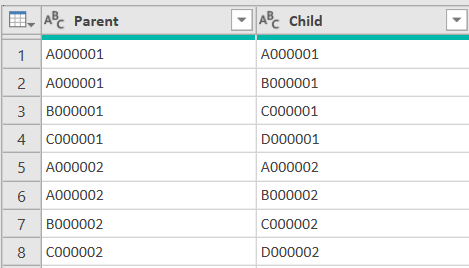
除了分割表格的功能,其实还可以通过使用Table.Split()使代码复杂化换取更高的运行效率(以下案例的附件需要在64位的Excel 2013或者更新的版本中运行)。假设现在需要把以下表格(DB)中Parent等同于Child的所有行提取出来:
经过无数次试验后,发现Table.SelectRows( DB, each Text.StartsWith( [Child], "A" ) )是已知的方法中效率最高的(每百万行的耗时不足5秒)。在得出这个结论前,曾经尝试过以下的方法:
let
InnerJoin=
Table.NestedJoin(
DB,
{"Parent","Child"},
Table.DuplicateColumn(DB, "Child", "DParent"),
{"DParent","Child"},
"NTable",
JoinKind.Inner
),
RemoveCol = Table.SelectColumns( InnerJoin, {"Parent", "Child"} )
in
RemoveCol
在InnerJoin步骤中, 首先构造了一个辅助表,这个辅助表的前两列与DB相同,第三列DParent与第二列Child完全相同。然后使用Table.NestedJoin()通过复合键{"Parent", "Child"}和复合键{"DParent", "Child"}的内连接把DB与其辅助表连接起来。内连接留下来的行都是Parent与Child的文本都相同的,但是会多出不需要的NTable列,所以最后需要使用Table.SelectColumns()移除Parent与Child之外的列。以下为这个方法在不同的数据量下所需要的运行时间:
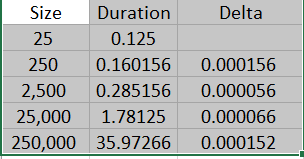
从上图中的最后一行可以得知,在百万行(250,000*4)的数据中运行以上代码需要将近36秒,将近为目前已知的最优解法的7倍。为了提升以上代码的运行效率,可以使用以下代码:
let
let
Outcome=
List.Accumulate(
List.Transform(
Table.Split(
DB,
1000
),
each Table.Buffer(_)
),
#table({},{}),
(x,y) ⇒
Table.Combine(
{
x,
Table.SelectColumns(
Table.NestedJoin(
y,
{"Parent","Child"},
Table.DuplicateColumn(y, "Child", "DParent"),
{"DParent","Child"},
"NTable",
JoinKind.Inner
),
{"Parent","Child"}
)
}
)
)
in
Outcome
以上代码,使用了Table.Split()从上至下把DB表格的每1000行分割为一个子表格,然后每一个子表格进行一次构建辅助表筛选Child和Parent的文本都相同的所有行,每一个子表格的结果将会通过使用Table.Combine()连接起来。
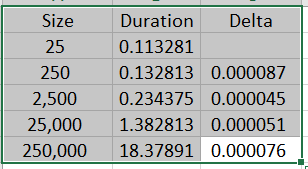
上图为使用Table.Split()后的运行时间,通过最后一行可以得知在百万行的数据中运行拆分表格的代码,可以减少将近50%的运行时间。为了让读者熟悉这个套路,以下给出实现同一目的的另一函数组合:
let
Outcome=
List.TransformMany(
List.Transform(
Table.Split(
DB,
900
),
each Table.Buffer(_)
),
each { Table.DuplicateColumn( _, "Child", "DParent" ) },
(x,y)⇒
Table.SelectColumns(
Table.NestedJoin(
x,
{"Parent","Child"},
y,
{"DParent","Child"},
"NTable",
JoinKind.Inner
),
{"Parent", "Child"}
)
)
in
Table.Combine( Outcome )
List.Accumulate()的组合是每产生一次筛选的结果就通过Table.Combine()进行一次表格的合并,而List.TransformMany()则是让每一筛选的结果依次成为串列的元素,得到{表格..表格}形式的串列后使用Table.Combine()一步完成所有表格合并。这个函数组合的效率稍微高于List.Accumulate()组合的效率,请参考如下图所示的运行时间:
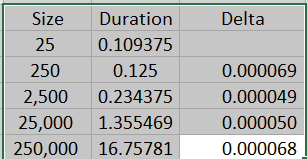
以上代码的y代入List.Count()后为1,这种情况下List.TransformMany()的代码都可以都用List.Transform()代替,请参考以下代码:
let
Outcome=
List.Transform(
List.Transform(
Table.Split(
DB,
900
),
each Table.Buffer(_)
),
each
Table.SelectColumns(
Table.NestedJoin(
_,
{ "Parent","Child" },
Table.DuplicateColumn( _, "Child", "DParent" ),
{ "DParent","Child" },
"NTable",
JoinKind.Inner
),
{ "Parent", "Child" }
)
)
in
Table.Combine( Outcome )
以上代码与List.TransformMany()组合高度相似就不再解释一遍,以下给出这种方法在不同数据量下运行时间:
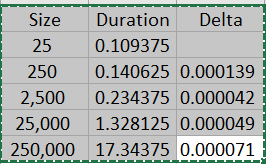
通过List.Transform()解决这个问题的效率也比List.Accumulate()稍微高一点,但是仍然与最优解相去甚远。以上的例子说明,通过使用Table.Split()合理地分割表格,在数据比较多的情况下是有可能大幅削减运行的时间,但是从实际操作来看合适的pageSize是非常难找的。
偷偷更新呀,目录里面没加上,都没看到
请教下如何汇总多工作簿下指定第二个sheet (每个sheet 名不一样),因为power query不能像VBA 一样 通过sheet 顺序号引用sheet 名
好像没有类似的功能,可以考虑内建一个参数表通过内连接把工作表筛选出来,再合并