归类是工作中最常见的问题之一,而其中离散值的区间匹配虽然逻辑简单,但在Power Query中需要谨慎选择现实的方法才不会在数据较多的情景下运行过久,下文将分享几种不同的方案。
区间匹配一般会根据类似下图的表格进行匹配(下文称Para):
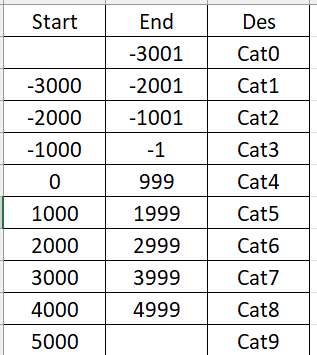
由于Table.Join()目前不支持不等式连接,最常见的实现方法为筛选参数表(详见如下):
let
Buffering = Table.Buffer(Para),
Add_TB =
Table.AddColumn(
DB,
"nTable",
(x)=>
Table.SelectRows(
Buffering,
(y)=> y[Start] <= x[Val] and y[End] >= x[Val]
)
),
Expansion =
Table.ExpandTableColumn(
Add_TB,
"nTable",
{"Des"}
),
Data_Type =
Table.TransformColumnTypes(
Expansion,
{
"Des",
type text
}
)
in
Data_Type
以上方案十分简洁,但由于Power Query对表格的操作较慢,使用第8代i7和16G内存处理百万级数据的运行时间逼近50秒,但只要把参数表化为列表,运行时间大幅减少至6.7秒左右,演示代码如下:
let
Buffering =
List.Buffer(
Table.ToRows(Para)
),
Add_TB =
Table.AddColumn(
DB,
"Des",
(x)=>
List.Select(
Buffering,
(y)=> y{0} <= x[Val] and y{1} >= x[Val]
){0}{2},
type text
)
in
Add_TB
另一种最容易想到的方案是手写多个if,虽然很麻烦,但出乎意料得高效,相同条件下运行的时间在4.6秒左右,代码如下:
let
Add_TB =
Table.AddColumn(
DB,
"nTable",
(x)=>
if
x[Val] >= 5000
then
"Cat9"
else if
x[Val] >= 4000
then
"Cat8"
else if
x[Val] >= 3000
then
"Cat7"
else if
x[Val] >= 2000
then
"Cat6"
else if
x[Val] >= 1000
then
"Cat5"
else if
x[Val] >= 0
then
"Cat4"
else if
x[Val] >= -1000
then
"Cat3"
else if
x[Val] >= -2000
then
"Cat2"
else if
x[Val] >= -3000
then
"Cat1"
else
"Cat0",
type text
)
in
Add_TB
由于Table.AddColumn()的第三个参数是函数,所以可以通过Expression.Evaluate()把文本转换为函数,从而避免手写多个if的痛苦,方法如下:
let
Source =
Expression.Evaluate(
"(x)=>"
﹠
Text.Combine(
Table.TransformRows(
Table.RemoveLastN(Para, 1),
(x)=>
Text.Format(
"if x[Val] <= #{0} then #{1}",
{
x[End],
Expression.Constant(x[Des])
}
)
)
﹠
{Expression.Constant(Table.Last(Para)[Des])},
" else "
)
)
in
Source
构建好以上函数后,就可以用作Table.AddColumn()的第三参数完成匹配了:
let
Add_TB =
Table.AddColumn(
DB,
"nTable",
F1,
type text
)
in
Add_TB
动态if方案处理百万级数据的运行时间与手写if的方案非常接近(4.6秒),虽然if方案会在区间变多的情况下变慢,但感觉实际情景很少有区间的数量会多于100,所以这个方案应该在大多数情景下仍能保持高效。接下来,介绍以List.PositionOf()为主体的方法(实测Table.PositionOf()会慢一点,在Power Query中表格操作比列表操作要慢):
let
Source = List.Buffer(Para[End]),
Dess = List.Buffer(Para[Des]),
Grp =
Table.AddColumn(
DB,
"Pos",
(x)=>
Dess{
List.PositionOf(
Source,
x[Val],
Occurrence.First,
(k,j)=>k>=j
)
},
type text
)
in
Grp
以上代码的大意为:
(1)把参数表的End列和Des列化为List并通过List.Buffer()缓冲至内存中;
(2)通过List.PositionOf找出所有大于或等于Val的最小End在列表中的相对位置;
(3)通过相对位置匹配出组别的描述
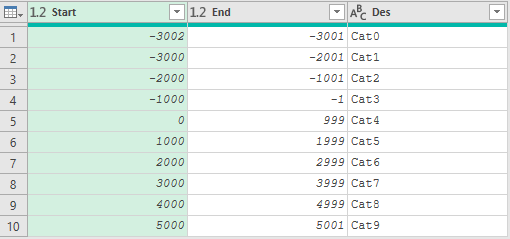
以List.PositionOf()为主体的方案比if方案稍慢,相同条件下大约耗时6秒,同时与if方案一样当区间数量变大时性能会下降。对于离散数值,还可以采用枚举法,即把参数表所有可能的数值枚举出来,然后通过内连接把区间找出来。枚举法需要设置两个极值,由于这种方案的效率很明显与这两个极值之差成反比,极值Ex_Val1设为第一个区间的End-1,极值Ex_Val2设为最后一个区间的Start+1,如下图所示:
枚举法的演示代码如下:
let
Add_Cap =
Table.AddColumn(
DB,
"Val_Adj",
each if
[Val] >= Ex_Val2
then
Ex_Val2
else if
[Val] <= Ex_Val1
then
Ex_Val1
else
[Val],
type number
),
//远比List.Min(List.Max())要快
Add_Col =
Table.AddColumn(
Para,
"Vals",
(x)=>{x[Start]..x[End]},
type list
),
Expansion = Table.ExpandListColumn(Add_Col, "Vals"),
Inner =
Table.Join(
Add_Cap,
"Val_Adj",
Expansion,
"Vals",
JoinKind.Inner
),
Col_Removal = Table.SelectColumns(Inner, {"Val", "Des"})
in
Col_Removal
以上代码的大意为:
(1)把小于等于Ex_Val1的Val限制为Ex_Val1和大于等于Ex_Val2的Val限制为Ex_Val2
(2)通过Table.AddColumn()和Table.ExpandListColumn()构造一个枚举每一个Des中所有可能值的表格
(3)通过DB和辅助表的连接找出Val对应的Des
枚举法在相同的条件下,运行时间为5.7秒,略比if方案慢,但涉及的函数较简单比较适合追求效率的新手,不过缺点是这种匹配方案只适用于离散数值以及随着需要枚举的可能值的数量增加,效率会随之下降。关于离散值的区间匹配,目前主流AI会建议使用二分法,该方案的演示代码如下:
let
Para_List = Table.ToColumns(Para),
S = List.Buffer(Para_List{0}),
E = List.Buffer(Para_List{1}),
D = List.Buffer(Para_List{2}),
Cnt = List.Count(D),
BS =
(value as number) as text =>
let
Search =
(low as number, high as number) =>
let
mid = Number.IntegerDivide(low + high, 2),
outcome =
if
value < S{mid}
then
@Search(low, mid-1)
else if
value > E{mid}
then
@Search(mid + 1, high)
else
D{mid}
in
outcome,
output = Search(0, Cnt-1)
in
output,
Result =
Table.AddColumn(
DB,
"Interval",
each BS([Val]),
type text
)
in
Result
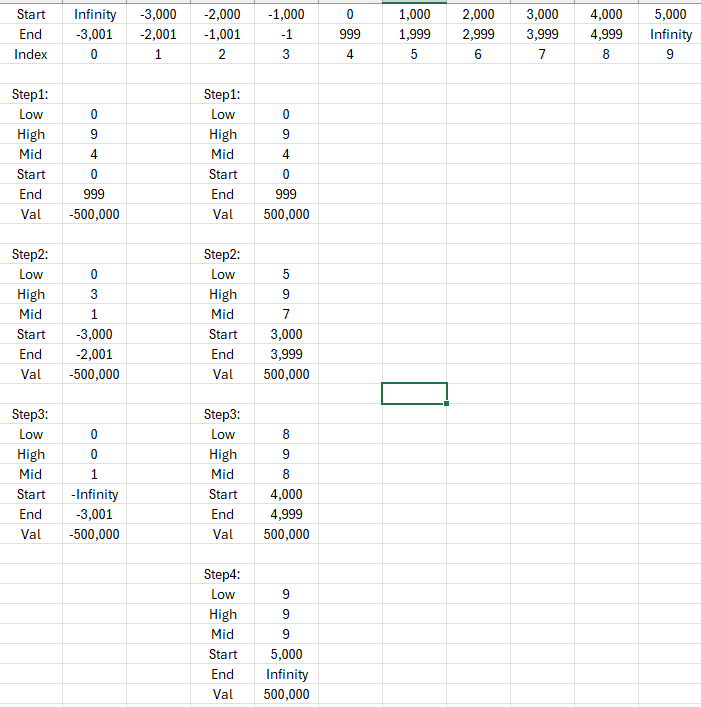
以上代码的大意为:从参数表中间的区间开始,如果Val比这个区间Start小,那么就往左边找,如果Val比这个区间End大,就往右边找,如果Val处于Start和End之间,说明已经找到所属的区间,往左或往右找时重复前面描述的所有动作。以下以500,000和-500,000作为例子分步说明这个方案的原理:
虽然受到一众AI的推荐,但这种方案在相同条件下需时10秒左右,很可能是递归在Power Query中效率不高。不难联想到,这种思路能够用来模仿以List.PositionOf()为主体的方案,演示代码如下:
let
E = List.Buffer(Para[End]),
D = List.Buffer(Para[Des]),
Cnt = List.Count(D),
BS = (val as number) as text =>
let
Pos =
(low as number, high as number) as number =>
let
mid = Number.IntegerDivide(low + high, 2),
search =
if
low > high
then
low
else if
E{mid} >= val
then
@Pos(low, mid-1)
else
@Pos(mid+1, high)
in
search,
Cat = D{Pos(0, Cnt-1)}
in
Cat,
Result =
Table.AddColumn(
DB,
"Interval",
each BS([Val]),
type text
)
in
Result
以上代码的大意为:从参数表中间的区间开始,如果Val小于等于这个区间的End,那么就往左边找否则就往右边找,当low大于high时,说明已经找到大于等于Val的最小End,。以下以-500,000作为例子分步说明这个方案的原理:

在相同条件下,以上方案运行时间大约11秒,略慢于AI推荐的方案,同时也说明在Power Query中自定义函数很难超越内建的函数。实际上不难发现,在参数表已知的情况下,二分法等效于以下if方案:
let
Add_TB =
Table.AddColumn(
DB,
"nTable",
each if
[Val] < 0
then
if
[Val] < -2000
then
if
[Val] <= -3001
then
"Cat0"
else
"Cat1"
else
if
[Val] <= -1001
then
"Cat2"
else
"Cat3"
else
if
[Val] < 2000
then
if
[Val] <= 999
then
"Cat4"
else
"Cat5"
else
if
[Val] < 4000
then
if
[Val] <= 2999
then
"Cat6"
else
"Cat7"
else
if
[Val] <= 4999
then
"Cat8"
else
"Cat9",
type text
)
in
Add_TB
很可惜的是,以上方案并没有显著地比普通的if方案快,那就不花时间通过Expression.Evaluate()进行动态化了。最后想比较一下在实战环境中(允许离散值存在重复),以上方案有没有超越几年前方案,旧方案代码如下:
let
Distinction =
List.Buffer(
List.Distinct(DB[Maturity_Date])
),
rTB =
Table.ExpandListColumn(
Table.AddColumn(
Para,
"Date",
(x)=>
List.Select(
Distinction,
(y)=> x[Start] <= y and x[End] >= y
),
type list
),
"Date"
),
Joining =
Table.Join(
DB,
"Maturity_Date",
rTB,
"Date",
JoinKind.Inner
),
Removal = Table.RemoveColumns(Joining, {"Date", "Start", "End"})
in
Removal
以上代码的大意为:
(1)对所有的Maturity_Date进行去重;
(2)在参数表Para中,添加一计算列寻找落入每一个区间中的Maturity_Date;
(3)以DB为左表,步骤(2)的结果为右表进行内连接
旧套路运行时间大约11.7秒,而对比之下以List.PositionOf()为主体的方案需时10.9秒。
总结下来,新发现如下:
(1)在Power Query中,一般在处理同一个问题时,以Table.开头的方案一般会比以List.开头的方案慢;
(2)在Power Query中,一般在处理同一个问题时,if方案会比其他等价的函数组合更快;
(3)在Power Query中, 自定义函数一般会比内建函数慢